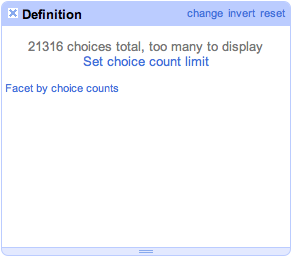
Google refineのクラスタリング機能は便利ですが、ファセット(facet)でバリエーションが多い場合は”too many to display”となってしまい実行出来ません。現バージョンでは制限を変えられるようになっていますが、それでもブラウザベースである程度大きなデータに対して処理を行うとブラウザが長時間にわたり重くなるという問題があります。
-
-
Google Refine: Facet Menu
-
-
Google Refine: Too many to display
その一方でソースコードは公開されているので、それを利用することで、上記の問題を回避したクラスタリングが可能になります。
Key collision については、Clusteringから個々のソースを取得して適宜生成します。
kNN については、下記の要領でダウンロードします。
svn checkout http://simile-vicino.googlecode.com/svn/trunk/ simile-vicino-read-only
ちなみに、kNNはGoogle refine中からは、kNNClustererで呼ばれています。
simile-vicino-read-onlyディレクトリに移動して ant を実行すると生成されます。そのままでも良いですが、下記の要領で jar ファイルとしておくのも可搬性が良くなるのでお薦めです。
jar -cvf simile-vicino.jar -C simile-vicino-read-only/build/classes/ .
以上でクラスタリングを下記の要領で実行することが出来ます。
java -cp ./simile-vicino-read-only/lib/secondstring-20100303.jar:simile-vicino.jar edu.mit.simile.vicino.Cluster <Distance> <Source> <radius> <block size>
PPMのときは、以下のライブラリも必要。
java -cp ./simile-vicino-read-only/lib/secondstring-20100303.jar:./simile-vicino-read-only/lib/arithcode-1.1.jar:simile-vicino.jar edu.mit.simile.vicino.Cluster PPM <Distance> <Source> <radius> <block size>
▼ Distanceは以下のいずれか。
- BZip2
- GZip
- Jaccard
- Jaro
- JaroWinkler
- JaroWinklerTFIDF
- Levenshtein
- PPM
▼ Sourceは一行一文字列のテキストファイルが想定。
▼ radiusはkNNの半径(倍精度浮動小数点)。
▼ block sizeは文字単位のnグラムによる距離を計算する際の、nの値。
